
Half&Half: Demystifying Intel's Directional Branch Predictors for Fast, Secure Partitioned Execution
IEEE Symposium on Security and Privacy (IEEE S&P), May 2023.
Hosein Yavarzadeh, Mohammadkazem Taram, Shravan Narayan, Deian Stefan, Dean Tullsen
[ Paper | bibtex | Slides | Teaser | Video ]
In this article, I will discuss our discoveries regarding the structure of the modern branch predictors within high-end Intel processors. For a thorough examination of our findings, please refer to our paper presented at the IEEE Symposium on Security and Privacy in 2023.
Before getting into the details of our findings, let me provide a brief overview of branch prediction in modern processors.
Without branch prediction, the processor would have to wait until the branch instruction is executed before it can determine the next instruction to fetch.
This would result in a significant performance penalty.
To overcome this issue, modern processors use branch predictors to predict the outcome of a branch instruction before it is executed.
This enables the processor to speculatively execute the predicted instructions, which can significantly improve performance if the branch predictor is accurate enough.
The branch prediction unit (BPU) in modern processors is resposible for making three key predictions:
Intel's conditional branch predictor (CBP) is a TAGE-like predictor that uses a combination of global and local history to predict the outcome of conditional branches.
Let's take a look at our findings regarding the architecture of Intel's CBP.
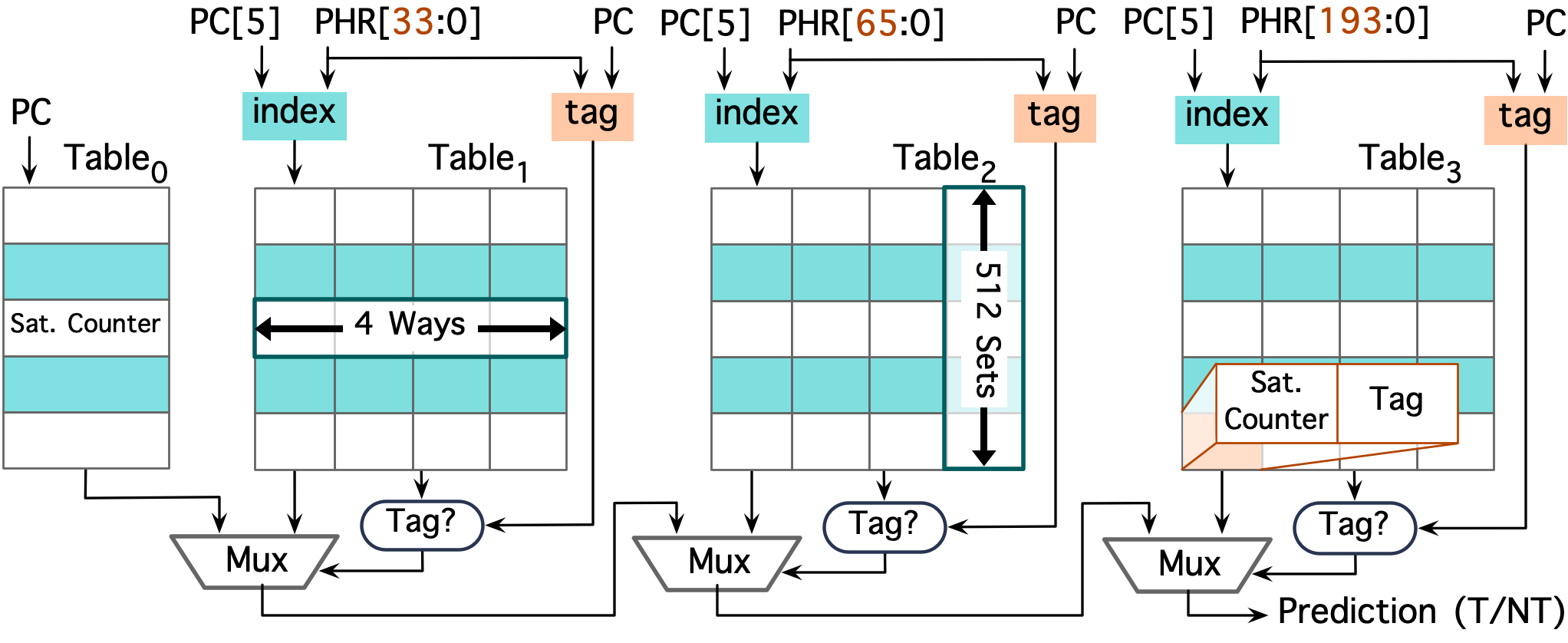
The local history component (Table0) is indexed using the lower bits of the branch instruction's address and is useful for capturing the local behavior of branches.
For example, it can capture the behavior of a conditional branch that is almost-always taken or not taken.
The global history components (Tables1-3) are indexed/tagged using the combination of the branch instruction's address and the path history register (PHR).
In the literature, the PHR is often referred to as the global history register (GHR) or the branch history buffer (BHB).
We found that in intel processors, the global history (PHR) gets updated only when the branch is taken which is different from the conventional GHR used in TAGE-like predictors.
GHR is like a shift register that gets updated based on the outcome of the branch --- inserts the outcome of the branch at the least significant bit and shifts the rest of the bits to the right.
However, in Intel's CBP, the PHR is updated only when the branch is taken, using a different mechanism.
When a branch is taken, a so called "footprint" value is computed based on the branch's address and the target address.
This "footprint" is then used to update the PHR.
For example, in Alder Lake processors, the footprint is computed (as depicted in the following figure) using the 16 lower bits of the branch's address and the 6 lower bits of the target address.

From a security standpoint, this final observation has enormous implications. It means that no branch for which PC[5] is 0 can possibly be influenced by branches for which PC[5] is 1, in any of the PHTs. They cannot cause evictions to reduce branch accuracy. They cannot detect evictions, eliminating side channels. They cannot mistrain branches because they cannot induce aliasing across this partition.
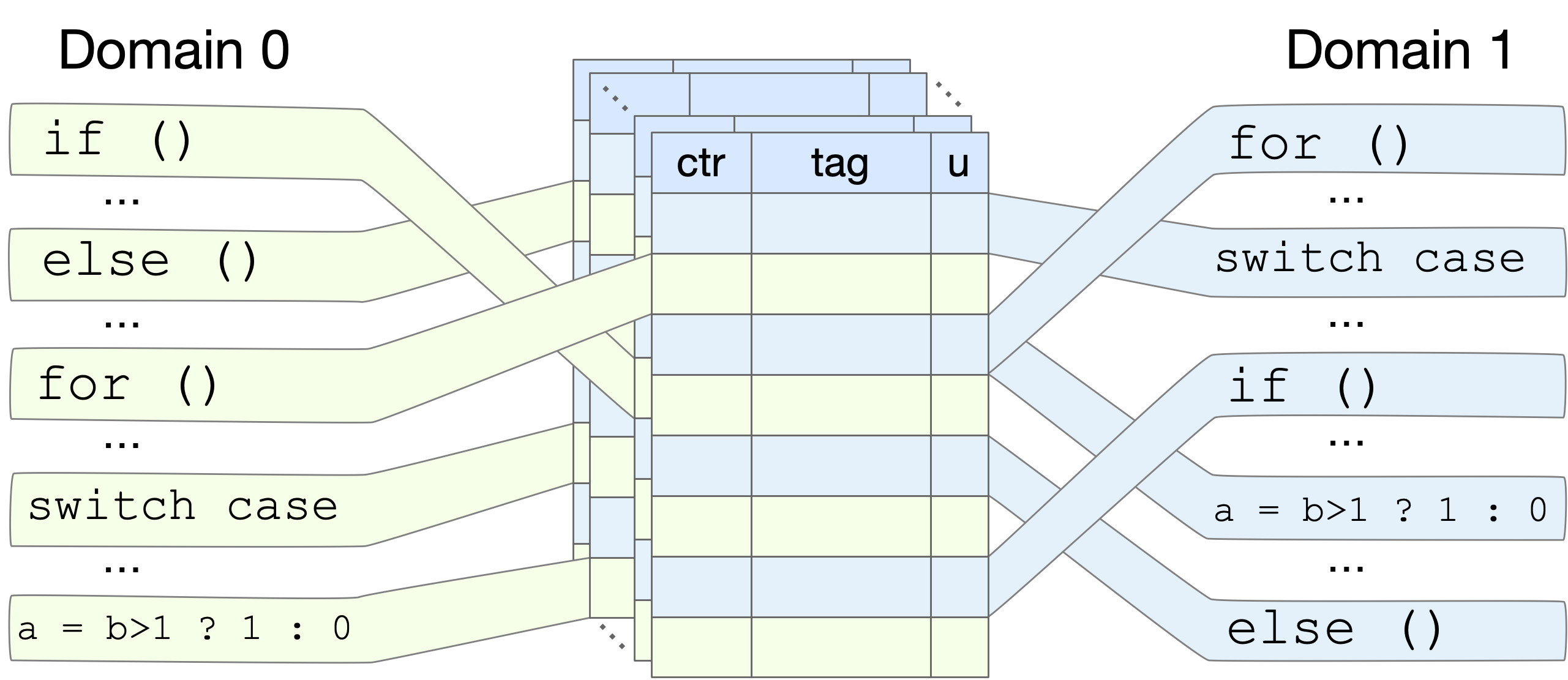
We have implemented this defense mechanism on top of LLVM and Swivel (hardened web-assembly compiler) compilers and evaluated it on a variety of Spectre-like attacks. Our results show that Half&Half is highly effective in mitigating these attacks, with minimal performance overhead.
We believe that Half&Half has the potential to significantly improve the security of modern processors against Spectre-like attacks, and we are excited to continue our work in this area.
Please do not hesitate to reach out to me at hyavarzadeh@ucsd.edu.